Glossary of AI Terms
AI EngineeringFor complete transparency the following is extracted and edited from Lenny's Newsletter as it succinctly captures the key concepts.
Model
An AI model is a computer program that is built to work like a human brain. You give it some input (i.e. a prompt), it does some processing, and it generates a response.
Like a child, a model “learns” by being exposed to many examples of how people typically respond or behave in different situations. As it sees more and more examples, it begins to recognize patterns, understand language, and generate coherent responses.
There are many different types of AI models. Some, which focus on language—like ChatGPT o3, Claude Sonnet 4, Gemini 2.5 Pro, Meta Llama 4, Grok 3, DeepSeek, and Mistral—are known as large language models (LLMs). Others are built for video, like Google Veo 3, OpenAI Sora, and Runway Gen-4. Some models specialize in generating voice, such as ElevenLabs, Cartesia, and Suno. There are also more traditional types of AI models, such as classification models (used in tasks like fraud detection), ranking models (used in search engines, social media feeds, and ads), and regression models (used to make numerical predictions).
LLM (large language model)
LLMs are text-based models, designed to understand and generate human-readable text. That’s why the name includes the word “language.”
Recently, most LLMs have actually evolved into “multi-modal” models that can process and generate not just text but also images, audio, and other types of content within a single conversational interface. For example, all of the ChatGPT LLM models natively support text, images, and even voice. This started with GPT-4o, where “o” stands for “omni” (meaning it accepts any combination of text, audio, and image input).
Here’s a really good primer on how LLMs actually work, and also this popular deep dive by Andrej Karpathy:
Transformer
The transformer architecture, developed by Google researchers in 2017, is the algorithmic discovery that made modern AI (and LLMs in particular) possible.
Transformers introduced a mechanism called “attention,” where instead of only being able to read text word‑by‑word, sequentially, the model is able to pay attention to all the words at once. This helps the models understand how words relate to each other, making them far better at capturing meaning, context, and nuance than earlier techniques.
Another big advantage of the transformer architecture is that it’s highly parallelizable—it can process many parts of a sequence at the same time. This makes it possible to train much bigger and smarter models simply by scaling up the data and compute power. This breakthrough is why we suddenly went from basic chatbots to sophisticated AI assistants. Almost every major AI model today, including ChatGPT and Claude, is built on top of the transformer architecture.
This is the best explanation of transformers I’ve seen. Here’s also a more technical and visual deep dive:
Training/Pre-training
Training is the process by which an AI model learns by analyzing massive amounts of data. This data might include large portions of the internet, every book ever published, audio recordings, movies, video games, etc. Training state-of-the-art models can take weeks or months, require processing terabytes of data, and cost hundreds of millions of dollars.
For LLMs, the core training method is called “next-token prediction.” The model is shown billions of text sequences with the last “token” (roughly analogous to a word, see definition of token below) hidden, and it learns to predict what word should come next.
As it trains, the model adjusts millions of internal settings called “weights.” These are similar to how neurons in the human brain strengthen or weaken their connections based on experience. When the model makes a correct prediction, those weights are reinforced. When it makes an incorrect one, they’re adjusted. Over time, this process helps the model improve its understanding of facts, grammar, reasoning, and how language works in different contexts. Here’s a quick visual explanation.
If you’re skeptical of next-token prediction generating novel insights and super-intelligent AI systems, here’s Ilya Sutskever (co-founder of OpenAI) explaining why it’s deceptively powerful:
Supervised learning
Supervised learning refers to when a model is trained on “labeled” data—meaning the correct answers are provided. For example, the model might be given thousands of emails labeled “spam” or “not spam” and, from that, learn to spot the patterns that distinguish spam from non-spam. Once trained, the model can then classify new emails it’s never seen before.
Most modern language models, including ChatGPT, use a subtype called “self-supervised learning.” Instead of relying on human-labeled data, the model creates its own labels, generally by hiding the last token/word of a sentence and learning to predict it. This allows it to learn from massive amounts of raw text without manual annotation.
Unsupervised learning
Unsupervised learning is the opposite: the model is given data without any labels or answers. Its job is to discover patterns or structure on its own, like grouping similar news articles together or detecting unusual patterns in a dataset. This method is often used for tasks like anomaly detection, clustering, and topic modeling, where the goal is to explore and organize information rather than make specific predictions.
Post-training
Post-training refers to all of the additional steps taken after training is complete to make the model even more useful. This includes steps like “fine-tuning*”* and “RLHF.”
Fine-tuning
Fine-tuning is a post-training technique where you take a trained model and do additional training on specific data that’s tailored to what you want the model to be especially good at. For example, you would fine-tune a model on your company’s customer service conversations to make it respond in your brand’s specific style, or on medical literature to make it better at answering healthcare questions, or on educational content for specific grade levels to create a tutoring assistant that explains concepts in age-appropriate ways.
This additional training tweaks the model’s internal weights to specialize its responses for your specific use case, while preserving the general knowledge it learned during pre-training.
Here’s an awesome technical deep dive into how fine-tuning works:
RLHF (reinforcement learning from human feedback)
RLHF is a post-training technique that goes beyond next-token prediction and fine-tuning by teaching AI models to behave the way humans want them to—making them safer, more helpful, and aligned with our intentions. RLHF is a key method used for what’s referred to as “alignment.”
This process works in two stages: First, human evaluators compare pairs of outputs and choose which is better, training a “reward model” that learns to predict human preferences. Then, the AI model learns through reinforcement learning—a trial-and-error process where it receives “rewards” from the reward model (not directly from humans) for generating responses the reward model predicts humans would prefer. In this second stage, the model is essentially trying to “game” the reward model to get higher scores.
Here’s a great guide, plus this technical deep dive into RLHF:
Prompt engineering
Prompt engineering is the art and science of crafting questions (i.e. “prompts”) for AI models that result in better and more useful responses. Like when you’re talking to a person, the way you phrase your question can lead to dramatically different responses. The same AI model will give very different responses based on how you craft your prompt.
There are two categories of prompts:
- Conversational prompts: What you send ChatGPT/Claude/Gemini when you’re having a conversation with it
- System/product prompts: The behind-the-scenes instructions that developers bake into products to shape how the AI product behaves
Here’s a podcast episode from just last week where we cover this and much more:
RAG (retrieval-augmented generation)
RAG is a technique that gives models access to additional information at run-time that they weren’t trained on. It’s like giving the model an open-book test instead of having it answer from memory.
When you ask a question like “How do this month’s sales compare to last month?” a retrieval system is able to search through your databases, documents, and knowledge repos to find pertinent information. This retrieved data is then added as context to your original prompt, creating an enriched prompt that the model then processes. This leads to a much better, more accurate answer.
One common source of “hallucinations” is when you don’t give the model the context it needs to answer your question through RAG.
Broadly, to summarize:
- Pre-training: Teaches the model general knowledge (and language)
- Fine-tuning: Specializes the model for specific tasks
- RLHF: Aligns the model with human preferences
- Prompt engineering: The skills of crafting better inputs to guide the model toward the most useful outputs
- RAG: A technique that retrieves additional relevant information from external sources at run-time to give the model up-to-date or task-specific context it wasn’t trained on
Here’s a great overview of fine-tuning vs. RAG vs. prompt engineering:
Evals
Evals (short for “evaluations”) are structured ways to measure how well an AI system performs on specific tasks, such as correctness, safety, helpfulness, or tone. They define what “good” looks like for your AI system and help you answer the question: Is this model doing what I want it to do?
Evals are basically unit tests or benchmarks for your AI product. They run your model through predefined inputs and compare its responses against expected outputs. This helps you quantify progress, catch regressions, and guide you toward improvements.
For example, here’s what an eval to measure the toxicity and tone of a model’s response might look like. Your model output would be inserted into the {text} variable:

Evals are often described by top product leaders as the most critical, yet overlooked, skill for building successful AI products:

Don’t miss this excellent guest post by Aman Khan that teaches you how to craft evals for your product.
Inference
Inference is when the model “runs.” When you ask ChatGPT a question and it generates a response, that’s it doing inference.
MCP (model context protocol)
MCP is a recently released open standard that allows AI models to interact with external tools—like your calendar, CRM, Slack, or codebase—easily, reliably, and securely. Previously, developers had to write their own custom code for each new integration.
MCP also gives the AI the ability to take actions through these tools, for example, updating customer records in Salesforce, sending messages in Slack, scheduling meetings in your calendar, or even committing code to GitHub.
It’s still early in the definition of AI protocols, and there are other competing proposals, like A2A from Google and ACP from BeeAI/IBM.
Here’s a really nice in-depth explanation of MCP:
Gen AI (generative AI)
Gen AI refers to AI systems that can create new content, such as text, images, code, audio, or video. This is opposed to models that just analyze or classify data, such as spam detection, fraud analysis, or image recognition models.
GPT (generative pre-trained transformer)
“GPT” captures the three key elements behind how state-of-the-art LLMs like ChatGPT 4.1, Claude Opus 4, Llama 4, and Grok 3 work:
- Generative: The model doesn’t just classify or analyze—it can generate new content.
- Pre-trained: It first learns general language patterns by being trained on massive amounts of text (as described above) and can then be fine-tuned for more specific tasks.
- Transformer: This refers to the breakthrough architecture (described above) that allows the model to understand context, relationships, and meaning across language.
The combination of these three ideas—generation, large-scale pre-training, and the transformer architecture—is what made tools like ChatGPT feel intelligent, coherent, and surprisingly useful across a wide range of tasks.
Token
A token is the basic unit of text that an AI model understands. For LLMs, this is sometimes a word, but often just a part of a word. There are analogous concepts like “patches” for image models and “frames” for voice models.
For example, “ChatGPT is smart.” might be split into the tokens “Chat,” “GPT,” “is,” “smart,” and “.” Even though “ChatGPT” is one word, the model breaks it into smaller pieces to make learning language more scalable, flexible, and efficient.
This explanation of transformers also explains tokens really well, and here you can see how top models tokenize words.
Here’s the paragraph above tokenized by GPT-4o:

Agent
An agent is an AI system designed to take actions on your behalf to accomplish a goal. Unlike chatbots like Claude or ChatGPT, which take a prompt and quickly respond with an answer, an agent can plan, work step-by-step, and use external tools, often across many apps or services, to achieve some outcome you set for it.
To borrow a definition from this recent guest post, “Make product management fun again with AI agents,” it’s best to think of the term “agent” as a spectrum, where AI systems become “agentic” the more of the following behaviors they exhibit:
- Acts proactively, ****as opposed to waiting to be prompted
- Makes its own plan, ****as opposed to being given instructions
- Takes real-world action, such as updating a CRM, running code, or commenting on a ticket—as opposed to only sharing recommendations
- Draws on live data, such as a web search or a customer support queue—as opposed to relying on static training or your manually uploading a file
- Creates its own feedback loop, ****where it watches its own output and iterates without human assistance
Here’s a great guide from Anthropic for how to build effective agents.
Vibe coding
The term originated from this tweet by Andrej Karpathy:
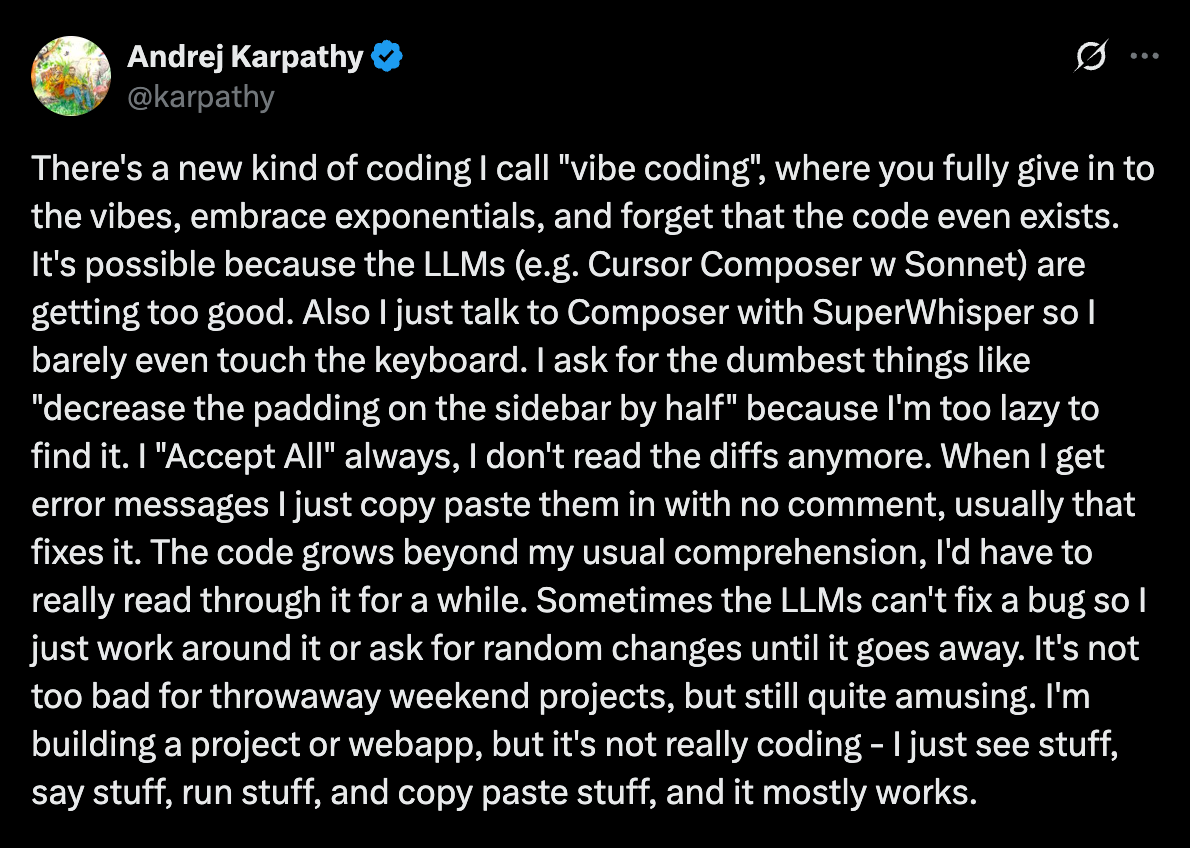
Vibe coding has come to mean building apps using AI tools like Cursor, Windsurf, Bolt, Lovable, v0, or Replit, by describing what you want in plain English (i.e. prompts) rather than writing code. In many cases, you never look at the code at all.
AGI (artificial general intelligence)
AGI refers to AI being “generally” smart—not just good at narrow tasks like coding, math, or data analysis, but capable of performing a wide range of tasks well, as well as learning how to tackle new problems without needing specialized training.
When people talk about reaching AGI, they usually mean the point where AI is more intelligent than the average human across most subjects. Some people believe we’ve already reached this point.
Artificial “superintelligence” (ASI) refers to the next step beyond AGI—AI that is much more intelligent than the best human minds in virtually every domain. We don’t believe we have reached this point yet, and there are debates about whether AGI to ASI will be a fast or slow takeoff.
Hallucination
A hallucination is when an AI model generates a response that sounds confident but is factually incorrect or entirely made up.
This happens because the model doesn’t actually “know” facts or look things up in a database. Instead, it generates responses by predicting the most likely next token/word based on patterns in its training data. When it lacks the right information, it may confidently fill in the gaps with something that sounds plausible but isn’t real.
The good news is that newer models are getting better at avoiding hallucination, and there are proven strategies—like RAG and prompt engineering—that help mitigate the risk (here’s a guide from Anthropic).
Synthetic data
To train ever more intelligent models, you need ever more data. But once the models are trained on the entire internet, every book ever published, every recording, dataset, etc., how do we give them more data? Part of the answer is “synthetic” data.
Synthetic data is artificially generated data. It follows the same patterns and structure as human-generated data, and, amazingly, it can be just as effective at helping models learn. It’s valuable when real data is limited, sensitive, or fully exhausted.
Synthetic data is generated differently depending on the type of data:
- Text: LLMs are prompted to generate fictional customer support chats, medical notes, or math problems based on real-world examples.
- Images: Diffusion models and GANs create realistic visuals, from street scenes to x-rays to product photos, without copying actual images.
- Audio: Voice and sound models synthesize speech, background noise, or music that mimic real recordings.
To a human, synthetic data can often be indistinguishable from real data, for example, a chatbot transcript that seems authentic but was entirely generated.